AI Infrastructure & MLOps Leader
Transforming enterprise AI ambitions into production-ready capabilities.
I design resilient AI foundations that connect data science, AI engineering, and application teams. My focus spans GPU clusters, Kubernetes ecosystems, and automated MLOps practices that keep innovation compliant, observable, and production-ready across cloud and on-prem estates.
Recent Roles & Impact

Lowe's
Senior Cloud & Platform Engineer · 2021 – PresentDriving enterprise AI infrastructure, GPU-ready Kubernetes platforms, and zero-downtime modernization programs across 140+ clusters.

Global Payments
Senior AWS DevOps Engineer · May 2020 – Sep 2021Automated PCI-compliant AWS environments, hardened CI/CD for payment APIs, and optimized observability for global transaction flows.

Object Computing Inc.
Senior Cloud Engineer (Consulting) · Apr 2017 – May 2020Designed Kubernetes & MLOps platforms for public-sector clients, unifying IaC, monitoring, and SRE practices across hybrid clouds.

North Dakota Dept. of Health
Consult Engagement via OCI · St. Louis, MOModernized HIPAA-governed data platforms, building secure Kubeflow pipelines and encrypted data services for statewide health teams.

Mastercard
Platform Engineer · May 2016 – Apr 2017Engineered resilient payment infrastructure, codified Terraform-based provisioning, and embedded compliance automation for global services.
AI Platform Highlights
GPU Video Analytics Platforms
Technical Lead for two enterprise AI/ML initiatives on GPU-enabled Kubernetes: real-time warehouse safety monitoring and in-store customer assistance with privacy-aware computer vision.
- Forklift & pallet tracking, employee safety compliance, high-res camera telemetry.
- Consent-based facial recognition, personalized recommendations, and realtime AI copilots for store associates.
- Built scalable RTSP ingestion (GStreamer, FFmpeg, DeepStream) with GPU buffering and burst resiliency.
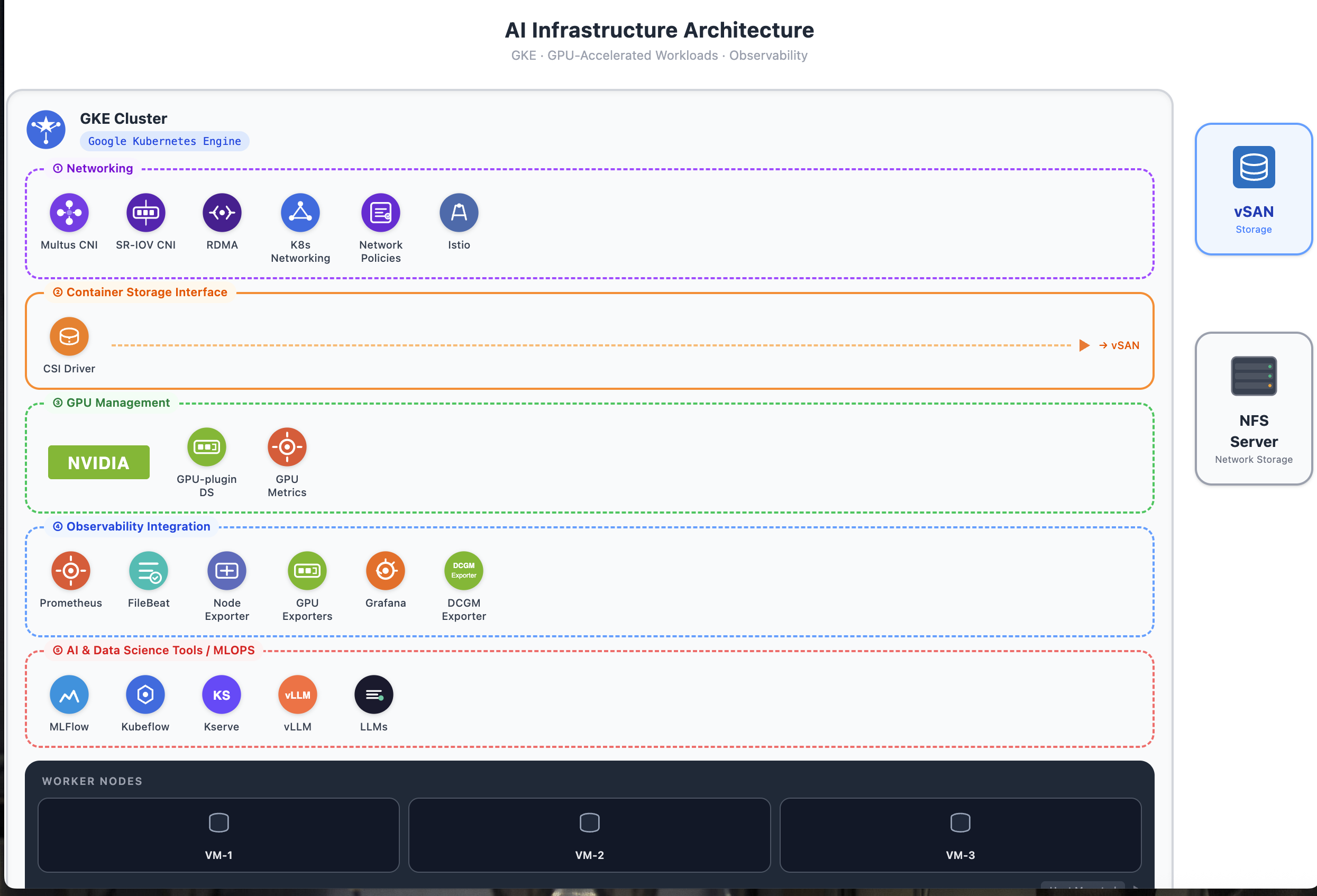
Kubeflow + Vertex AI Platform
Integrated Kubeflow with GPU-enabled node pools, RBAC, namespace isolation, Istio ingress, object storage, and distributed training operators, complemented by managed Vertex AI services.
- Autoscaled inference and batch prediction on A100, H100, L4, and T4 GPU tiers with versioned rollouts.
- Traffic splitting, model lineage, and GPU autoscaling for mission-critical workloads.
- Distributed training using PyTorch DDP, Horovod, and MPI across on-prem NVIDIA DGX racks.
Observability & Networking for AI
Built observability stacks and high-performance Kubernetes networking tailored for GPU-heavy AI systems across retail, payments, and healthcare environments.
- Unified logging, tracing, and GPU telemetry (Prometheus, Grafana, DCGM) for 140+ clusters.
- Multi-tenant Istio meshes, private ingress, and RDMA networking for low-latency inference.
- HIPAA-compliant data paths, encrypted storage, and policy-driven governance for regulated workloads.
Business Impact
This platform enables data science, AI engineering, and application teams to rapidly build, train, deploy, and operate machine learning and generative AI workloads while maintaining enterprise requirements for scalability, security, governance, observability, and operational reliability. It serves as a reusable AI foundation capable of supporting model development, distributed training, real-time inference, and large-scale production AI deployments across multiple business domains.
Rapid Development
Accelerate AI model development and deployment with streamlined workflows and automated pipelines.
Enterprise Security
Maintain enterprise-grade security, governance, and compliance across all AI workloads.
Scalability
Scale from prototype to production with infrastructure that grows with your business needs.
Real-time Inference
Deploy models for real-time inference with low latency and high throughput.
Observability
Gain comprehensive insights into model performance and system health.
Production Ready
Built for large-scale production AI deployments with operational reliability.
Enterprise AI Infrastructure Architect
Designing Scalable AI Platforms & GPU Infrastructure
Designing scalable AI platforms, GPU infrastructure, Kubernetes ecosystems, and MLOps solutions for enterprise machine learning, distributed training, and large-scale LLM inference workloads. Specialized in Kubernetes, NVIDIA GPU platforms, Kubeflow, MLflow, KServe, vLLM, RDMA networking, and cloud-native automation across GCP, Azure, AWS, and on-premises environments.